Incorporate keeping track of accuracy into X (previously Twitter)
tl;dr: Incorporate keeping track of accuracy into X1. This contributes to the goal of making X the chief source of information, and strengthens humanity by providing better epistemic incentives and better mechanisms to separate the wheat from the chaff in terms of getting at the truth together.
Why do this?

- Because it can be done
- Because keeping track of accuracy allows people to separate the wheat from the chaff at scale, which would make humanity more powerful, more formidable.
- Because it is an asymmetric weapon, like community notes, that help the good guys who are trying to get at what is true much more than the bad guys who are either not trying to do that or are bad at it.
- Because you can’t get better at learning true things if you aren’t trying, and current social media platforms are, for the most part, not incentivizing that trying.
- Because rival organizations—like the New York Times, Instagram Threads, or school textbooks—would be made more obsolete by this kind of functionality.
Core functionality
I think that you can distill the core of keeping track of accuracy to three elements2: predict, resolve, and tally. You can see a minimal implementation of this functionality in <60 lines of bash here.
predict
make a prediction. This prediction could take the form of
- a yes/no sentence, like “By 2030, I say that Tesla will be worth $1T”
- a probability, like “I say that there is a 70% chance that by 2030, Tesla will be worth $1T”
- a range, like “I think that by 2030, Tesla’s market cap will be worth between $800B and $5T”
- a probability distribution, like “Here is my probability distribution over how likely each possible market cap of Tesla is by 2030”
- more complicated options, e.g., a forecasting function that gives an estimate of market cap at every point in time.
I think that the sweet spot is on #2: asking for probabilities. #1 doesn’t capture that we normally have uncertainty about events—e.g., in the recent superconductor debacle, we were not completely sure one way or the other until the end—, and it is tricky to have a system which scores both #3-#5 and #2. Particularly at scale, I would lean towards recommending using probabilities rather than something more ambitious, at first.
Note that each example gave both a statement that was being predicted, and a date by which the prediction is resolved.
resolve
Once the date of resolution has been reached, a prediction can be marked as true/false/ambiguous. Ambiguous resolutions are bad, because the people who have put effort into making a prediction feel like their time has been wasted, so it is good to minimize them.
You can have a few distinct methods of resolution. Here are a few:
- Every question has a question creator, who resolves it
- Each person creates and resolves their own predictions
- You have a community-notes style mechanism for resolving questions
- You have a jury of randomly chosen peers who resolves the prediction
- You have a jury of previously trusted members, who resolves the question
- You can use a Keynesian Beauty Contest, like Kleros or UMA, where judges are rewarded for agreeing with the majority opinion of other judges. This disincentivizes correct resolutions for unpopular-but-true questions, so I would hesitate before using it.
Note that you can have resolution methods that can be challeged, like the lower court/court of appeals/supreme court system in the US. For example, you could have a system where initially a question is resolved by a small number of randomly chosen jurors, but if someone gives a strong signal that they object to the resolution—e.g., if they pay for it, or if they spend one of a few “appeals” tokens—then the question is resolved by a larger pool of jurors.
Note that the resolution method will shape the flavour of your prediction functionality, and constrain the types of questions that people can forecast on. You can have a more anarchic system, where everyone can instantly create a question and predict on it. Then, people will create many more questions, but perhaps they will have a bias towards resolving questions in their own favour, and you will have slightly duplicate questions. Then you will get something closer to Manifold Markets. Or you could have a mechanism where people propose questions and these are made robust to corner cases in their resolution criteria by volunteers, and then later resolved by a jury of volunteers. Then you will get something like Metaculus, where you have fewer questions but these are of higher quality and have more reliable resolutions.
Ultimately, I’m not saying that the resolution method is unimportant. But I think there is a temptation to nerd out too much about the specifics, and having some resolution method that is transparently outlined and shipping it quickly seems much better than getting stuck at this step.
tally
Lastly, present the information about what proportion of people’s predictions come true. E.g., of the times I have predicted a 60% likelihood of something, how often has it come true? Ditto for other percentages. These are normally binned to produce a calibration chart, like the following:
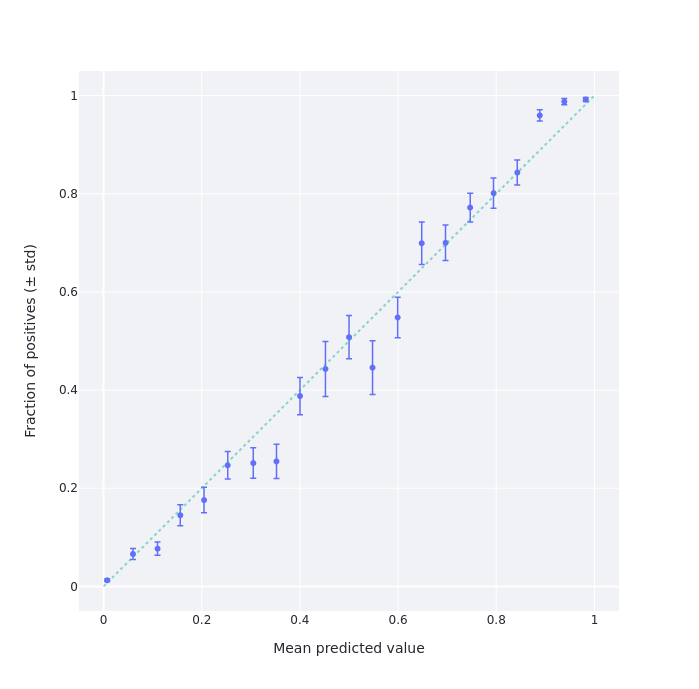
On top of that starting point, you can also do more elaborate things:
- You can have a summary statistic—a proper scoring rule, like the Brier score or a log score—that summarizes how good you are at prediction “in general”. Possibly this might involve comparing your performance to the performance of people who predicted in the same questions.
- Previously, you could have allowed people to bet against each other. Then, their profits would indicate how good they are. I think this might be too complicated at Twitter style, at least at first.
Here is a review of some mistakes people have previously made when scoring these kinds of forecasts. For example, if you have some per-question accuracy reward, people will gravitate towards forecasting on easier rather than on more useful questions. These kinds of considerations are important, particularly since they will determine who will be at the top of some scoring leaderboard, if there is any such. Generally, Goodhart’s law is going to be a problem here. But again, having some tallying mechanism seems way better than the current information environment.
Once you have some tallying—whether a calibration chart, a score from a proper scoring rule, or some profit it Musk-Bucks3, such a tally could:
- be semi-prominently displayed so that people can look to it when deciding how much to trust an account,
- be used by X’s algorithm to show more accurate accounts a bit more at the margin,
- provide an incentive for people to be accurate,
- provide a way for people who want to become more accurate to track their performance
When dealing with catastrophes, wars, discoveries, and generally with events that challenge humanity’s ability to figure out what is going on, having these mechanisms in place would help humanity make better decisions about who to listen to: to listen not to who is loudest but to who is most right.
Conclusion
X can do this. It would help with its goal of outcompeting other sources of information, and it would do this fair and square by improving humanity’s collective ability to get at the truth. I don’t know what other challenges and plans Musk has in store for X, but I would strongly consider adding this functionality to it.