Grow vs stay small for startup nonprofits (2026/03/04)
Small startup nonprofits, such as those from Charity Entrepreneurship, face the tradeoff between staying smaller, and thus by default more cost-effective per unit of money, and grow, and accept diminishing returns but larger impact. The second seems worth doing because it unlocks more impact as a whole.
The first order analysis: Producing impact at scale is worth the reduction in cost-effectiveness.In the financial markets, getting a larger return for more capital is harder. Berkshire Hathaway is holding $382 billion in cash, because they can’t find good enough returns, say 20%/year, at that size. But as a private individual, one can get those returns via private investments, education, exploring career opportunities, changing jobs, or following niche market trends. But as one’s capital size gets high enough, one can’t deploy that capital without moving markets too much, and one starts to need ritualized financial instruments, like stocks rather than handshake agreements.
Similarly, even though a scrappy nonprofit with a few talented people is more cost-effective, the number of those opportunities is limited. For instance, there might be only so many areas of operation, or only so many talented people willing to do so. Or, even if Charity Entrepreneurship is able to find a growing number of people to lead those small organizations, the rate at which CE itself can grow is limited.
For less capable people He wrote the Mahābhārata (2026/03/03)
Our hero, Arjuna, finds himself in a position of either fighting his cousins, who have gone to war against him, or losing his kingdom and abandoning his duty as a warrior. As he surveys the battlefield, he turns to Krishna, who is taking the form of his charioteer, and inquires about how to make this decision and the nature of the good life.
The answer is a recipe: realize that pursuing happiness and pleasure is a trap. The fulfillment of a craving simply results in another craving. You might be tempted to solve this by getting really rich and then fulfilling all your cravings, but then you will find that old age, disease and death are not solvable through wealth [^yet].
The solution presented to the trap is to cultivate tranquility and serenity, through ample heaps of loving-kindness meditation (on the figure of Krishna). To be unattached from the fruit of one’s actions but nonetheless do one’s duty. And to orient one’s life around a combination of attaining wisdom, loving devotion, and doing good actions.
Therefore, Arjuna should kill his cousins and regain his kingdom, following his duty. In so doing he should regard Krishna in awe and hold him in constant adoration.
When rich Americans fail (2026/02/16)
American’s base needs are met. American culture, for the rich Americans I get along with, is incredibly messed up, where people’s base needs are met (something historically uncommon), so they focus on the higher needs (acceptance, self-actualization, impact, status).
This is historically unusual. This state of affairs is historically uncommon. GDP per capita was lower than 10K even in the US and UK until early last century, and the world as a whole only reached that level in the 2000s.
Leading to pathologies. Instincts and ingrained patterns of behavior are trained in a domain where there are no superstimuli, and because neither culture nor biology has had enough training time in a domain of such abundance, they may fail to align short-term wants with long-term flourishing. Further, higher needs are less objectively defined, and indeed perhaps only defined with reference to one’s ingroup. So the strands of mimetic desire go awry as they are defined in an unanchored Keynesian Beauty contest
Dear forecaster (2025/07/07)
People come to askaforecaster.com, and magic ball tells us all. Because they are willing to pay for an answer, questions tend to be interesting, and I’ve found it very meaningful to answer them. The below has been lightly edited for anonymity and published with the clients' permission.
For $150: Will AI eat my product design job?Dear forecaster,
Current AI tools are augmenting work for engineers at many technology companies. The same thing is happening for non-engineering product-related roles as well – for instance, Product Designers are having AI included in design tools to create interface mock-ups faster; Product Managers are using LLMs to write drafts of briefs and memos; etc. Presumably, as these tools improve employee efficiency, companies will need to hire fewer and fewer employees to get the same amount of output.
Memo on the grain of truth problem (2024/12/04)
Frameworks that try to predict reality can fail when they miss crucial details. Frameworks about AI have each failed in turn. For instance:
- Future Shock, Alvin Toffler, 1970: Higher adaptation ability than anticipated, sometimes manifested as constantly shifting goalposts for what is “AGI”.
- The Singularity is Near, Ray Kurzweil, 2005: We aren’t seeing a discrete singularity, but rather continuous improvement. No nanotechnology.
- Superintelligence, Nick Bostrom, 2014, or MIRI, 2010s: AI isn’t a single-minded, fanatical forceful and elegant agent. So far, AI is much more of a tool (Google maps) than an agent (James Bond).
- Age of Em, Robin Hanson, 2016: AI isn’t first achieved by cloning specific humans digitally.
- Reframing superintelligence, Eric Drexler, 2019: LLMs turn out to be generalist models, not many specialist models trading with each other.
What is a dollar (2024/12/01)
A dollar is a promise. A promise that you will be able to acquire goods and services from Americans. But it is not a specific promise for specific goods, but a vague promise. It is however a promise with momentum, and the rest of the world has coordinated around the power of the dollar for trade. This is powerful insofar as dollar-denominated markets outcompete other coordination methods.
Up to 1971, a dollar was a promise for a specific amount of gold, so the track record of our new type of dollar isn’t that long, just a bit over fifty years. Importantly, this fiat system hasn’t survived a world war. If China tried to invade Taiwan, and the US mobilized its economy when entering a war to prevent that, this system of fiat money might not survive.
More esoterically, the distribution of dollars is a mechanism of coordination between some groups against others: the rich against the poor, the old against the young, the Americans against everyone else. As dollars become more concentrated, at some point the young and dispossessed might be better off coordinating using a different currency built anew, rather than orienting their lives around taking care of older and richer people whose grip on them is through the dollar.
At that level of abstraction, it seems a more salient possibility to me that the American financial system dies not through a fairer distribution of dollars, but through replacing the dollar with a different coordination method. This description sounds innocent, but the process could become violent, akin to peasant revolts. The specific way it might manifest could be through something like the EU’s Directive on the Resilience of Critical Entities, where some industries are categorized as “critical entities” and employees can’t quit, must work.
The share of the surface of the earth in very urban areas is roughly ~0.3% (2024/10/16)
The share of the surface of the Earth which is very urban turns out to be a recurring question when estimating various catastrophic risks, like asteroids or volcanoes. Once we estimate the frequency of such events, we want to estimate the chance that they’d hit an urban area.
There is some pre-existing literature on the topic, but I thought that making my own estimate would be quicker and easier to fit with my estimation problem.
My methodology was to download this List of cities with over one million inhabitants from Wikipedia, then use a script to fetch the area in kilometers from the Wikipedia infobox. I chose to take the metropolitan area when this existed, i.e., including urban sprawl. I did not include the giant “prefecture-level” Chinese cities of Chongqing and Jilin, though I did include the “macrometropolis” around São Paulo.
My initial script had to be improved a fair bit, since not all cities had infoboxes, or in the same format. The final version can be seen here. In addition, I complemented it with some manual data gathering, either still from the Wikipedia page, or roughly estimating city size from Google maps. Finally, I manually checked for transcription errors (I had a few, particularly mixing up prefectures and cities, or taking the population number instead of surface area).
What’s the chance your startup will succeed? (2024/09/10)
The baserate for all companiesThe U.S. Bureau of Labor Statistics shares data on the survivorship rates of a all companies. Around 30-35% die before the third year, and around 50% by the fifth year, with surprising regularity. Of all 4.66M companies founded in the year 2000, 2.7M remain, or 18.2%. This seems like a good starting point, or baserate.
The BLS also shares data disaggregated by industry. For instance, for the information or technical services fields. But the numbers look pretty similar for all industry (with agriculture dying substantially less often and mining dying substantially more often)

No, the country of “no taxation without representation” doesn’t take a 30% tax on payments to foreigners (2024/08/30)
A slightly abstruse tax issue affecting non-US contractors for US organizations is that sometimes such organizations ask for a W-8BEN form, but that form asks you to claim tax treaty benefits. What should you do if you live in a country which doesn’t have such a tax treaty, or are digital nomad, and are not a US citizen?
What is the original purpose of form W8-BEN? What are the laws pertaining non-US resident taxation?The W8-BEN form withholding “is imposed on the gross amount paid and is generally collected by withholding under section 1441” (see purpose of form). But section 1441, withholding of tax on nonresident aliens, states:
Except as otherwise provided in subsection ©, all persons, in whatever capacity acting (including lessees or mortgagors of real or personal property, fiduciaries, employers, and all officers and employees of the United States) having the control, receipt, custody, disposal, or payment of any of the items of income specified in subsection (b) (to the extent that any of such items constitutes gross income from sources within the United States), of any nonresident alien individual or of any foreign partnership shall (except as otherwise provided in regulations prescribed by the Secretary under section 874) deduct and withhold from such items a tax equal to 30 percent thereof, except that in the case of any item of income specified in the second sentence of subsection (b), the tax shall be equal to 14 percent of such item.
Simple electoral college simulation (2024/06/02)
Here is a simple model of the US electoral college. It aims to be conceptually simple and replicatable. It incorporates data from state-specific polls, and otherwise defaults to the state’s electoral history baserate.
Other projects, like 538, Nate Silver’s substack or Gelman’s model are to this project as a sportscar is to a walking stick. They are much more sophisticated, and probably more accurate. However, they are also more difficult to understand and to maintain.
Compare with: Nuño’s simple node version manager, squiggle.c, Predict, Resolve & Tally
What stories does the model tell?Unflattering aspects of Effective Altruism (2024/03/05)
1. I want to better understand in order to better decideAs a counterbalance to the rosier and more philosophical perspective that Effective Altruism (EA) likes to present of itself, I describe some unflattering aspects of EA. These are based on my own experiences with it, and my own disillusionments1.
If people getting into EA2 have a better idea of what they are getting into, and decide to continue, maybe they’ll think twice, interact with EA less naïvely and more strategically, and not become as disillusioned as I have.
But also, the EA machine has been making some weird and mediocre moves, leaving EA as a whole as a not very formidable army3. A leitmotiv from the Spanish epic poem The Song of the Cid is “God, what a good knight would the Cid be, if only he had a good lord to serve under”. As in the story of the Cid then, so in EA now. As a result, I think it makes sense for the rank and file EAs to more often do something different from EA™, from EA-the-meme. To notice that taking EA money carries costs. To reflect on whether the EA machine is better than their outside options. To walk away more often.
A Bayesian Nerd-Snipe (2024/02/25)
Consider the number of people you know who share your birthday. This seems an unbiased estimate of the number of people who, if they had been born the same day of the year as you, you’d know—just multiply by 365. That estimate itself is an estimate of how many people one knows at a somewhat non-superficial level of familiarity.
I asked my Twitter followers that question, and this is what they answered:
How many people do you know that were born in the same day of the year as you?
— Nuño Sempere (@NunoSempere) February 21, 2024
Now, and here comes the nerd snipe: after seeing the results of that poll, what should my posterior estimate be for the distribution of how many people my pool of followers knows enough that they’d know their birthdays if they fell on the same day as one’s own?
Alternative Visions of Effective Altruism (2023/12/27)
IntroEA was born out of a very specific cultural milieu, and holds a very specific yet historically contingent shape. So what if instead EA had been…
Effective Altruism DistributedDay-trading the crypto to liberate the animals:
AI safety forecasting questions (2023/12/06)
tl;dr: This document contains a list of forecasting questions, commissioned by Open Philanthropy as part of its aim to have more accurate models of future AI progress. Many of these questions are more classic forecasting questions, others have the same shape but are unresolvable, still others look more like research projects or like suggestions of data gathering efforts. Below we give some recommendations of what to do with this list, mainly to feed them into forecasting and research pipelines. In a separate document, we outline reasons why using forecasting for discerning the future of AI may prove particularly difficult.
Table of Contents- Recommendations
- Questions
- Recurring terms
Auftragstaktik (2023/11/30)
Auftragstaktik is a method of command and delegation where the commander gives subordinates a clearly-defined objective, high-level details, and the tools needed to accomplish their objective. The subordinates have clear operational freedom, which leaves command to focus on architecting strategic decisions.
It has an interesting historical and semi-mythical background. After Napoleon outclassed the rest of Europe, the Prussians realized that they needed to up their game, and developed this methodology. With it, Germany became a military superpower. These days, though, armies have given up on having independent and semi-insubordinate general troops, and instead the Auftragstaktik stance seems to be reserved for special forces, like e.g., Navy Seals.
But beyond the semi-historical overview from the last paragraph, the idea of Auftragstaktik is useful to me as an ideal to aspire to implement. It is my preferred method of command, and my preferred method of being commanded. It stands in contrast to micromanaging. It avoids alienation as characterized by Marx, where the worker doesn’t have control of their own actions, which kills the soul. Corny as it sounds, if you have competent subordinates, why not give them wide berth to act as special forces rather than as corporate drones?
A while ago, I cleaned up a bit the Wikipedia page on this concept, and now I am writting this post so that it becomes more widely known across my circles. We need more people to carry A Message to Garcia, but independence benefits from a system of incentivization and control that enables it.
Hurdles of using forecasting as a tool for making sense of AI progress (2023/11/07)
IntroductionIn recent years there have been various attempts at using forecasting to discern the shape of the future development of artificial intelligence, like the AI progress Metaculus tournament, the Forecasting Research Institute’s existential risk forecasting tournament/experiment, Samotsvety forecasts on the topic of AI progress and dangers, or various questions osn INFER on short-term technological progress.
Here is a list of reasons, written with early input from Misha Yagudin, on why using forecasting to make sense of AI developments can be tricky, as well some casual suggestions of ways forward.
Excellent forecasters and Superforecasters™ have an imperfect fit for long-term questionsBrief thoughts on CEA’s stewardship of the EA Forum (2023/10/15)
Epistemic status: This post is blunt. Please see the extended disclaimer about negative feedback here. Consider not reading it if you work on the EA forum and don’t have thick skin.
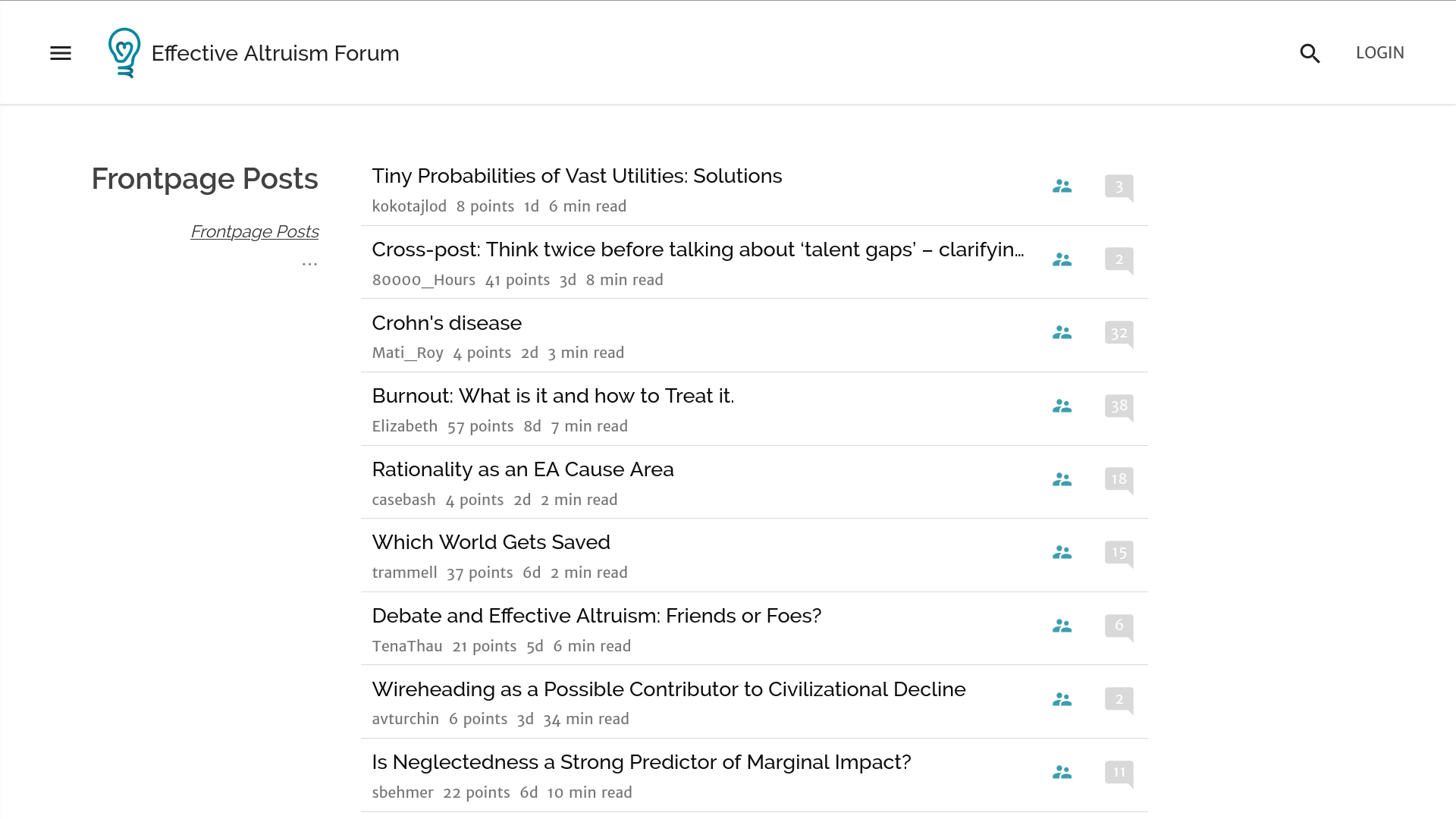
tl;dr: Once, the EA forum was a lean, mean machine. But it has become more bloated over time, and I don’t like it. Separately, I don’t think it’s worth the roughly $2M/year1 it costs, although I haven’t modelled this in depth.
The EA forum frontpage through time.
In 2018-2019, the EA forum was a lean and mean machine:
Count words in <50 lines of C (2023/09/15)
The Unix utility wc counts words. You can make simple, non-POSIX compatible version of it that solely counts words in 159 words and 42 lines of C. Or you can be like GNU and take 3615 words and 1034 lines to do something more complex.
Desiderata- Simple: Just count words as delimited by spaces, tabs, newlines.
- Allow: reading files, piping to the utility, and reading from stdin—concluded by pressing Ctrl+D.
- Separate utilities for counting different things, like lines and characters, into their own tools.
Quick thoughts on Manifund’s application to Open Philanthropy (2023/09/05)
Manifund is a new effort to improve, speed up and decentralize funding mechanisms in the broader Effective Altruism community, by some of the same people previously responsible for Manifold. Due to Manifold’s policy of making a bunch of their internal documents public, you can see their application to Open Philanthropy here (also a markdown backup here).
Here is my perspective on this:
- They have given me a $50k regranting budget. It seems plausible that this colors my thinking.
- Manifold is highly technologically competent.
- Effective Altruism Funds, which could be the closest point of comparison to Manifund, is not highly technologically competent. In particular, they have been historically tied to Salesforce, a den of mediocrity that slows speed, makes interacting with their systems annoying, and isn’t that great across any one dimension.
Incorporate keeping track of accuracy into X (previously Twitter) (2023/08/19)
tl;dr: Incorporate keeping track of accuracy into X1. This contributes to the goal of making X the chief source of information, and strengthens humanity by providing better epistemic incentives and better mechanisms to separate the wheat from the chaff in terms of getting at the truth together.
Why do this?
- Because it can be done
Webpages I am making available to my corner of the internet (2023/08/14)
Here is a list of internet services that I make freely available to friends and allies, broadly defined—if you are reading this, you qualify. These are ordered roughly in order of usefulness.
search.nunosempere.comsearch.nunosempere.com is an instance of Whoogle. It presents Google results as they were and as they should have been: without clutter and without advertisements.
Readers are welcome to make this their default search engine. The process to do this is a bit involved and depends on the browser, but can be found with a Whoogle search. In past years, I’ve had technical difficulties around once every six months, but tend to fix them quickly.
squiggle.c (2023/08/01)
squiggle.c is a self-contained C99 library that provides functions for simple Monte Carlo estimation, based on Squiggle. Below is a copy of the project’s README, the original, always-up-to-date version of which can be found here
Why C?- Because it is fast
- Because I enjoy it
- Because C is honest
Why are we not harder, better, faster, stronger? (2023/07/19)

In The American Empire has Alzheimer’s, we saw how the US had repeatedly been rebuffing forecasting-style feedback loops that could have prevented their military and policy failures. In A Critical Review of Open Philanthropy’s Bet On Criminal Justice Reform, we saw how Open Philanthropy, a large foundation, spent and additional $100M in a cause they no longer thought was optimal. In A Modest Proposal For Animal Charity Evaluators (ACE) (unpublished), we saw how ACE had moved away from quantitative evaluations, reducing their ability to find out which animal charities were best. In External Evaluation of the Effective Altruism Wiki, we saw someone spending his time less than maximally ambitiously. In My experience with a Potemkin Effective Altruism group (unpublished), we saw how an otherwise well-intentioned group of decent people mostly just kept chugging along producing a negligible impact on the world. As for my own personal failures, I just come out of having spent the last couple of years making a bet on ambitious value estimation that flopped in comparison to what it could have been. I could go on.
Those and all other failures could have been avoided if only those involved had just been harder, better, faster, stronger. I like the word “formidable” as a shorthand here.
Some melancholy about the value of my work depending on decisions by others beyond my control (2023/07/13)
For the last few years, while I was employed at the Quantified Uncertainty Research Institute, a focus of my work has been on estimating impact, and on doing so in a more hardcore way, and for more speculative domains, than the Effective Altruism community was previously doing. Alas, the FTX Future Fund, which was using some of our tools, no longer exists. Open Philanthropy was another foundation which might have found value in our work, but they don’t seem to have much excitement and apetite for the “estimate everything” line of work that I was doing. So in plain words, my work seems much less valuable than it could have been [1].

Part of my mistake [2] here was to do work whose value depended on decisions by others beyond my control. And then given that I was doing that, not making sure those decisions came back positive.
I have made this mistake before, which is why it stands out to me. When I dropped out of university, it was to design a randomized controlled trial for ESPR, a rationality camp which I hoped was doing some good, but where having some measure of how much could be good to decide whether to greatly scale it. I designed the randomized trial, but it wasn’t my call to decide whether to implement it, and it wasn’t. Pathetically, some students were indeed randomized, but without gathering any pre-post data. Interesting, ESPR and similar programs, like ATLAS, did scale up, so having tracked some data could have been decision relevant.
Betting and consent (2023/06/26)
There is an interesting thing around consent and betting:
- Clueless people can’t give fully informed consent around taking some bets I offer,
- because if they were fully informed, they wouldn’t make the bet, because they would know that I’m a few levels above them in terms of calibration and forecast accuracy.
- But on the other hand, they can only acquire the “fully informed” state about their own bullshitting after losing the bet,
- because once you lose money it is much harder to spin up rationalizations.
People’s choices determine a partial ordering over people’s desirability (2023/06/17)
Consider the following relationship:
Relative values for animal suffering and ACE Top Charities (2023/05/29)
tl;dr: I present relative estimates for animal suffering and 2022 top Animal Charity Evaluators (ACE) charities. I am doing this to showcase a new tool from the Quantified Uncertainty Research Institute (QURI) and to present an alternative to ACE’s current rubric-based approach.
Introduction and goalsAt QURI, we’re experimenting with using relative values to estimate the worth of various items and interventions. Instead of basing value on a specific unit, we ask how valuable each item in a list is, compared to each other item. You can see an overview of this approach here.
In this context, I thought it would be meaningful to estimate some items in animal welfare and suffering. I estimated the value of a few a few animal quality-adjusted life-years—fish, chicken, pigs and cows—relative to each other. Then I using those, I estimated the value of top and standout charities as chosen by ACE (Animal Charity Evaluators) in 2022.
Updating in the face of anthropic effects is possible (2023/05/11)
Status: Simple point worth writting up clearly.
Motivating exampleYou are a dinosaur astronomer about to encounter a sequence of big and small meteorites. If you see a big meteorite, you and your whole kin die. So far you have seen n small meteorites. What is your best guess as to the probability that you will next see a big meteorite?
In this example, there is an anthropic effect going on. Your attempt to estimate the frequency of big meteorites is made difficult by the fact that when you see a big meteorite, you immediately die. Or, in other words, no matter what the frequency of big meteorites is, conditional on you still being alive, you’d expect to only have seen small meteorites so far. For instance, if you had reason to believe that around 90% of meteorites are big, you’d still expect to only have seen small meteorites so far.
Review of Epoch’s Scaling transformative autoregressive models (2023/04/28)
We want to forecast the arrival of human-level AI systems. This is a complicated task, and previous attempts have been kind of mediocre. So this paper proposes a new approach.
The approach has some key assumptions. And then it needs some auxiliary hypotheses and concrete estimates flesh out those key assumptions. Its key assumptions are:
- That a sufficient condition for reaching human-level performance might be indistinguishability: if you can’t determine whether a git repository was produced by an expert human programmer or by an AI, this should be a sufficient (though not necessary) demonstration for the AI to have acquired the capability of programming.
- That models' performance will continue growing as predicted by current scaling laws.
A flaw in a simple version of worldview diversification (2023/04/25)
SummaryI consider a simple version of “worldview diversification”: allocating a set amount of money per cause area per year. I explain in probably too much detail how that setup leads to inconsistent relative values from year to year and from cause area to cause area. This implies that there might be Pareto improvements, i.e., moves that you could make that will result in strictly better outcomes. However, identifying those Pareto improvements wouldn’t be trivial, and would probably require more investment into estimation and cross-area comparison capabilities.1
More elaborate versions of worldview diversification are probably able to fix this flaw, for example by instituting trading between the different worldview—thought that trading does ultimately have to happen. However, I view those solutions as hacks, and I suspect that the problem I outline in this post is indicative of deeper problems with the overall approach of worldview diversification.
This post could have been part of a larger review of EA (Effective Altruism) in general and Open Philanthropy in particular. I sent a grant request to the EA Infrastructure Fund on that topic, but alas it doesn’t to be materializing, so that’s probably not happening.
A Soothing Frontend for the Effective Altruism Forum (2023/04/18)
Aboutforum.nunosempere.com is a frontend for the Effective Altruism Forum. It aims to present EA Forum posts in a way which I personally find soothing. It achieves that that goal at the cost of pretty restricted functionality—like not having a frontpage, or not being able to make or upvote comments and posts.
UsageInstead of having a frontpage, this frontend merely has an endpoint:
General discussion thread (2023/04/08)
Do you want to bring up something to me or to the kinds of people who are likely to read this post? Or do you want to just say hi? This is the post to do it.
Why am I doing this?Well, the EA Forum was my preferred forum for discussion for a long time. But in recent times it has become more censorious. Specifically, it has a moderation policy that I don’t like: moderators have banned people I like, like sapphire or Sabs, who sometimes say interesting things. Recently, they banned someone for making a post they found distasteful during April Fools in the EA forum—whereas I would have made the call that poking fun at sacred cows during April Fools is fair game.
So overall it feels like the EA Forum has become bigger and like it cares less about my values. Specifically, moderators are much more willing than I am to trade off the pursuit of truth in exchange for having fewer rough edges. Shame, though perhaps neccessary to turtle down against actors seeking to harm one.